2014/03/27
LDAP 登録用スクリプト
以前、某社内のユーザ管理を ldap 化した際に作成した
ldap 登録用の ldif ファイルを生成するスクリプト。
漢字の名字と名前を入力すると kakashi を利用して
ひらがなの名字、名前、ローマ字の名字、名前を自動的に取得し
ldap 登録用の ldif ファイルを生成して ldap 登録まで自動で行う。
当初は csv 型式のファイルから必要な情報を取得して
連続で ldap に登録するバッチスクリプトとして作成したのだが、
初期登録が完了した後はたまに発生するユーザの追加処理にのみ使用するので
対話的に実行するコマンドに作り直した。
漢字をひらがな/ローマ字に変換するために kakashi とnkf が必要になる。
漢字のよみは自動では完全には取得できないので変換した値を確認する様にしている。
ローマ字の氏名は私の趣味で名字は全て大文字、名前はキャピタライズとしている。
1#!/bin/sh 2# All rights reserved, copyright (C) 2014, Mitzyuki IMAIZUMI 3# 4 5# ldap 用設定 6passwd="password" 7org="dc=example,dc=com" 8 9# コマンド定義 10id="`/usr/bin/id -u`" 11kakasi=/usr/bin/kakasi 12slappasswd="/usr/sbin/slappasswd -h {md5}" 13toutf="/usr/bin/nkf -w" 14toeuc="/usr/bin/nkf -e" 15ldapadd="/usr/bin/ldapadd -x -D cn=Manager,${org}" 16ldappasswd="/usr/bin/ldappasswd -x -D cn=Manager,${org}" 17ldapsearch="/usr/bin/ldapsearch -LL -x -D cn=Manager,${org}" 18 19# uid 格納ファイル 20uidnum=/etc/uid 21 22# OU 選択肢 23oulist="Board Sales Develop Affair" 24 25# 入力用タイトル 26_uid="ユーザID" 27_sn="漢字名字" 28_gn="漢字名前" 29_hsn="名字よみ" 30_hgn="名前よみ" 31_tel="内線番号" 32_ou="所属" 33 34# 35# 汎用入力処理 36# $1: 入力された値を格納する変数名 37# $2: 必須フラグ 38# 39getans() 40{ 41 42 title=`eval "echo \\$_$1"` 43 var=$1 44 require=${2:-true} 45 46 while true 47 do 48 echo -n "${title} を入力して下さい: " 49 read ans 50 51 if [ -z "${ans}" ] 52 then 53 if ${require} 54 then 55 echo "${title} の入力は必須です" 56 else 57 echo "${titoe} なし" 58 break 59 fi 60 else 61 break 62 fi 63 done 64 65 eval "$var=${ans}" 66 67} 68 69# 70# カナ確認/入力処理 71# $1: 入力された値を格納する変数名 72# 73getkana() 74{ 75 76 title=`eval "echo \\$_$1"` 77 var=$1 78 79 echo -n "${title} は \"${2}\" で正しいですか?([y]/n): " 80 read ans 81 if [ "${ans}" = "n" ] 82 then 83 getans ${var} 84 else 85 eval "$var=${2}" 86 fi 87 88} 89 90# 91# 所属選択処理 92# $1: 入力された値を格納する変数名 93# 94getou() 95{ 96 97 title=`eval "echo \\$_$1"` 98 var=$1 99 100 while true 101 do 102 i=1 103 set ${oulist} 104 for o 105 do 106 echo "${i} ) ${o}" 107 i=`expr ${i} + 1` 108 done 109 echo -n "${title} を選択して下さい: " 110 read ans 111 if [ "${ans}" -ge 1 -a "${ans}" -lt $i ] 112 then 113 eval "$var=\${$ans}" 114 break 115 else 116 echo "入力が不正です" 117 fi 118 done 119 120} 121 122# 123# UID 取得処理 124# 125getuid() 126{ 127 128 num=`cat ${uidnum}` 129 expr ${num} + 1 > ${uidnum} 130 131} 132 133# 134# People 用 ldif ファイルの生成 135# 136ladduser() 137{ 138 139 cat <<-EOF | ${toutf} 140 dn: uid=${uid},ou=People,${org} 141 uid: ${uid} 142 objectclass: posixAccount 143 objectclass: top 144 objectclass: shadowAccount 145 objectclass: inetOrgPerson 146 cn: ${sn} ${gn} 147 cn: ${hsn} ${hgn} 148 cn: ${rgn} ${rsn} 149 sn: ${rsn} 150 givenname: ${rgn} 151 mail: ${uid}@example.com 152 o: Example, Inc. 153 ou: ${ou} 154 loginShell: /bin/bash 155 uidNumber: ${num} 156 gidNumber: ${num} 157 homeDirectory: /home/${uid} 158 gecos: ${rgn} ${rsn} 159EOF 160 test -n "${tel}" && echo "telephoneNumber: ${tel}" 161 echo 162 163} 164 165# 166# Group 用 ldif ファイルの生成 167# 168laddgroup() 169{ 170 171 cat <<-EOF | ${toutf} 172 dn: cn=${uid},ou=Group,${org} 173 objectclass: posixGroup 174 objectclass: top 175 cn: ${uid} 176 userPassword: {crypt}x 177 gidNumber: ${num} 178 memberUid: ${uid} 179 180EOF 181 182} 183 184# 185# ID が既に使用済みか確認する 186# $1: ID 187# 188existldap() 189{ 190 191 if ! egrep -q "^${1}:" /etc/passwd 192 then 193 return `${ldapsearch} uid=${1} -w ${passwd} | grep uid | wc -l` 194 else 195 return 1 196 fi 197 198} 199 200# 201# メイン処理 202# 203if [ "${id}" != "0" ] 204then 205 echo "root にて実行して下さい" 1>&2 206 exit 255 207fi 208 209# 情報入力 210while true 211do 212 while true 213 do 214 getans "uid" 215 if existldap ${uid} 216 then 217 break 218 fi 219 echo "${uid} は既に使用されています" 1>&2 220 done 221 getans "sn" 222 getans "gn" 223 gettel "tel" false 224 getkana "hsn" "`echo ${sn} | ${toeuc} | ${kakasi} -JH | ${toutf}`" 225 getkana "hgn" "`echo ${gn} | ${toeuc} | ${kakasi} -JH | ${toutf}`" 226 getou "ou" 227 228 echo 229 for i in uid sn gn hsn hgn tel 230 do 231 eval "echo \$_$i: \$$i" 232 done 233 234 echo -n "この情報で正しいですか?([y]/n): " 235 read ans 236 if [ "${ans}" != "n" ] 237 then 238 break 239 fi 240done 241 242# ローマ字表記の名字取得(全て大文字) 243rsn=`echo ${hsn} | ${toeuc} | ${kakasi} -Ha -Ka -Ja -Ea -ka | tr '[a-z]' '[A-Z]'` 244# ローマ字表記の名前取得(キャピタライズ) 245rgn=`echo ${hgn} | ${toeuc} | ${kakasi} -Ha -Ka -Ja -Ea -ka | awk '{ print toupper(substr($0, 1, 1)) substr($0, 2, length($0) - 1) }'` 246getuid 247# People 登録 248ladduser | ${ldapadd} -w ${passwd} 249# Group 登録 250laddgroup | ${ldapadd} -w ${passwd} 251# パスワード自動生成 252${ldappasswd} uid=${uid},ou=People,${org} -w ${passwd}
あまり需要がないとは思うけど折角なので公開してみる。
2014/03/25
キャピタライズ
英単語の先頭を大文字に置換する処理をキャピタライズというが、
このキャピタライズ処理を unix 標準のコマンドで実装しようという話。
置換と言えばまず思い浮かぶのが sed (1) なのだが、
GNU 拡張された sed (1) の場合は簡単に置換が可能なのだが、
FreeBSD の標準の sed (1) では簡単にいかない。
- GNU sed の場合
-
$ echo "foo" | sed 's/\(.\)\(.*\)/\U\1\L\2/g' Foo
GNU 拡張された sed (1) には \U と /L という 演算子があるので大文字、小文字変換が簡単に可能である。
- FreeBSD 標準の sed の場合
-
$ echo "foo" | sed 's/\(.\)\(.*\)/\U\1\L\2/g' UfLoo
FreeBSD 標準の sed (1) だと正しく変換されない。
- awk を利用した場合
-
sed (1) ではなく awk (1) を利用すれば
FreeBSD でもキャピタライズ処理は簡単にできる。
$ echo "foo" | awk '{ print toupper(substr($0, 1, 1)) substr($0, 2, length($0) - 1) }' Foo
awk (1) には大文字変換関数が実装されているので、 切り出した1文字目を大文字変換すれば簡単に実現できる。
- FreeBSD で sed を利用した場合
-
どうしても FreeBSD の sed (1) を利用したい場合、
tr (1) も併用する事にはなるが以下の処理で可能だ。
$ eval `echo "foo" | sed 's/\(.\)\(.*\)/\/bin\/echo -n \1 | tr "[a-z]" "[A-Z]"; echo \2/g'` Foo
sed (1) でtr (1) を利用した置換スクリプトを出力して eval (1) で実行した結果を表示しているのだが もはやネタとしか思えなくもない。
良い子は真似しないで下さい(笑
2014/03/04
C9A4 V6 650 + docomo 携帯での通信設定
CX-5 のメイカー純正カーナビゲーション ALPINE C9A4 V6 650 を
docomo の携帯電話と Bluetooth 接続して通信設定をしていたのだが、
先日、携帯電話を変更してからデータ通信が出来なくなっていた。
ナビゲーションと携帯電話は Bluetooth でペアリングが出来ていて
音声通話などは普通に利用できているのだが、
ナビゲーション側から地図データの差分更新などのデータ通信を開始すると
「接続できませんでした」というエラーが表示されてしまい
データ通信ができない状況だった。
データ通信のために接続を開始している携帯電話の画面を参照すると
mopera.ne.jp に接続しようとして切断されているのが確認できたが、
現在 docomo の携帯によるデータ通信は
mopera.net に接続する必要があるので、
以下の操作で C9A4 V6 650 に初期設定されている接続先を
mopera.net に変更する事で無事にデータ通信が可能となった。
- 画面左下の 設定 ボタンクリック
- 画面右上の 設定・編集 をタッチ
- 画面右下の Bluetooth設定 をタッチ
- Bluetooth機器設定の右にある 変更 をタッチ
- 選択リストから利用している Bluetooth 機器(携帯)をタッチ
- 画面下の 通信接続先 をタッチ
- 選択リストから NTT docomo FOMA / パケット通信 をタッチ
- 画面下の 詳細設定 をタッチ
- 電話番号の「*99***1#」を「*99***3#」に変更
なお、データ通信には大量のパケット通信が発生するので
パケット通信代が非常に高額になってしまう可能性もあるので、
十分に気をつけて設定する必要がある。
2014/02/06
OSX の pkgutil コマンド
OSX で .pkg 型式のインストーラを実行する時に
このパッケージは、ソフトウェアをインストールできるかどうかを判断するプログラムを実行します。
多くの場合は問題なくインストールできるのだが、 稀に
より新しいバージョンのソフトウェアがインストールされているのでインストールできません
的なメッセージでインストーラが終了してしまう場合がある。この様な場合、大抵は /Applications フォルダ等に存在する 該当のアプリケーションを削除するだけで 新しいアプリケーションのインストールが可能となるのだが、 ごくごく稀に削除しただけではインストーラが同じメッセージを表示してしまい インストール出来ない場合がある。
そもそも OSX の場合、アンインストーラが附属する一部のアプリケーション以外は
ファインダなどで /Applications フォルダの
アプリケーションアイコンをみ箱にドラッグするなどして削除すれば
アンインストールできるのだが、
それだけだと設定情報やインストール情報などがシステムに残ってしまう可能性がある。
ところが OSX の標準型式に準拠したインストーラからインストールされたソフトウェアは
pkgutil (1) コマンドを利用する事で
アプリケーションや設定情報などを完全に消去でき、
殆どの場合は上記インストーラによるチェックも問題なく通過できる様になる。
pkgutil (1) コマンドの基本的な利用方法
- 現在インストールされているパッケージ名の一覧を表示する。
$ pkgutil --pkgs
$ pkgutil --files パッケージ名
実行する場合は管理者権限が必要なので sudo (8) などで 管理者権限を取得する必要がある。
# pkgutil --unlink パッケージ名
実行する場合は管理者権限が必要なので sudo (8) などで 管理者権限を取得する必要がある。
# pkgutil --forget パッケージ名
pkgutil を実行する事でパッケージのインストール情報を完全に削除できるので、 アプリケーションを完全に削除したい場合は便利。
2014/02/01
ショルダーバッグ
ちょっと遅めのクリスマスプレゼント 兼 すごく遅めの誕生日プレゼントとして
ショルダーバッグを貰った。
シボ感のある上質な革を使用したシンプルで上品なショルダーバッグで、
デザインも容量も使い勝手も質感も全てが気に入っている。
たまたま遊びに行った羽田空港の国際線ターミナルのショップで見かけて、
お互いに一目で気に入った 輪怐・LIN-KUのショルダーバッグ。

普段ちょっと出かける時などに財布や携帯電話、サングラスケースなど
ちょっとしたモノを入れて気軽に持ち運べるバッグが欲しかったので、
まさにうってつけの素敵なバッグと出会えて非常に重宝している。
なかなか品質の良い皮革を使用しているとの事なので、
ちゃんと手入れをすればこの先何十年も愛用できると思う。
良い感じに使いこまれた革の表情を想像すると今から楽しみだ。
2014/01/16
爪切り
長年愛用していた爪切りの刃が欠けてしまったので、
複数の知人から絶賛されていた木屋の爪切りを購入した。
そもそも木屋というのは創業1792年の包丁などで有名な老舗らしく、
その老舗が丹精こめて作ったという爪切りの逸品らしい。
一般的に売られている爪切りはステンレス製の刃を採用しているが、
こちらの製品の刃は何と鋼製でまるで包丁の様な仕上げ。

小型ながら持った感じもずっしりと重くて、
控えめながら「道具」としての主張も忘れていない感じ。
爪を切る度にしっかりした手応えのある重さを感じる事ができ、
その度に「良い道具を使っている」という自己満足に浸れる(笑)。

今や 100円均一でも爪切りは買えるのだが、 たかだか数千円で爪を切る度にちょっとだけ良い気分になれるのは ある意味で安上がりな幸せじゃないかと思う。
2013/11/23
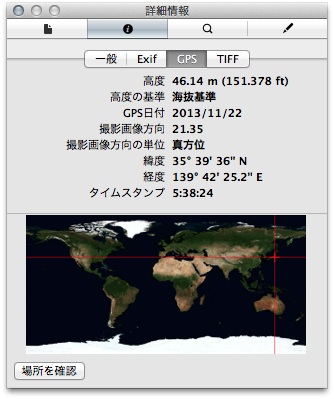
Exif 情報から GPS の緯度/経度情報を削除する
例によって こちら のブログをネタに
他人の褌で相撲を取る記事です。
元記事では Exif 情報を操作する時に、
バイナリを直接操作するのではなく
od (1) を利用してバイナリをテキスト型式に変換し、
テキスト操作した後で再度バイナリ型式に戻すという
正統的な手法でのアプローチをしています。
しかし dd (1) を利用すると
シェルスクリプトからバイナリを操作できるので、
バイナリ型式の画像を直接操作してしまうというアプローチを取ってみます。
画像ファイルに格納されている Exif 情報を簡単に解析して
GPS 情報を格納している領域 (GPSInfoIFD) から
緯度/経度情報だけをゼロに置換する処理となっています。
流石にシェル芸では無理なのでシェルスクリプトです。
1#!/bin/sh 2 3# 4# Endian を考慮して 4 バイト数字を取得する 5# 一度 od(1) で 16 進数に変換しバイト並びを修正した後に 10 進数に変換する 6# 7# $1: ファイル 8# $2: オフセット 9# 10get4Byte() 11{ 12 13 if [ ${endian} = "MM" ] 14 then 15 printf "%d" `dd if="${1}" bs=1 skip=${2} count=4 2> /dev/null | od -x | 16 sed -n "s/^0000000 *\(..\)\(..\)[ ]*\(..\)\(..\)/0x\2\1\4\3/p"` 17 else 18 printf "%d" `dd if="${1}" bs=1 skip=${2} count=4 2> /dev/null | od -x | 19 sed -n "s/^0000000 *\(..\)\(..\)[ ]*\(..\)\(..\)/0x\1\2\3\4/p"` 20 fi 21 22 23} 24 25# 26# Endian を考慮して 2 バイト数字を取得する 27# 一度 od(1) で 16 進数に変換しバイト並びを修正した後に 10 進数に変換する 28# 29# $1: ファイル 30# $2: オフセット 31# 32get2Byte() 33{ 34 35 if [ ${endian} = "MM" ] 36 then 37 printf "%d" `dd if="${1}" bs=1 skip=${2} count=2 2> /dev/null | od -x | 38 sed -n "s/^0000000 *\(..\)\(..\)/0x\2\1/p"` 39 else 40 printf "%d" `dd if="${1}" bs=1 skip=${2} count=2 2> /dev/null | od -x | 41 sed -n "s/^0000000 *\(..\)\(..\)/0x\1\2/p"` 42 fi 43 44} 45 46# 47# 任意の長さの文字列を取得する 48# 49# $1: ファイル 50# $2: オフセット 51# $3: 文字列長 52# 53getString() 54{ 55 56 dd if="${1}" bs=1 skip=${2} count=${3} 2> /dev/null 57 58} 59 60# 61# GPSInfoIFD の解析を行い緯度/経度情報をクリアする 62# 63# $1: ファイル 64# $2: GPSInfoIFD のタグ数 65# $3: GPSInfoIFD のオフセット位置 66# 67gps() 68{ 69 70 local i j offset tag val 71 72 i=0 73 74 while [ ${i} -lt ${2} ] 75 do 76 # GPSInfoIFD のタグ情報 77 offset=`expr ${3} + 14 + \( ${i} \* 12 \)` 78 tag=`get2Byte "${1}" ${offset}` 79 # タグ種類 80 # 2: 緯度 81 # 4: 経度 82 if [ ${tag} -eq 2 -o ${tag} -eq 4 ] 83 then 84 # データの数とデータのオフセットを取得 85 # 緯度/経度情報は値のタイプに RATIONAL(8バイト長) が指定されている 86 num=`get4Byte "${1}" \`expr ${offset} + 4\`` 87 val=`get4Byte "${1}" \`expr ${offset} + 8\`` 88 89 # 情報を削除するためにオフセットから 8 * データの数をゼロクリア 90 dd if=/dev/zero of="${1}" bs=1 conv=notrunc \ 91 seek=`expr ${val} + 12` count=`expr ${num} \* 8` 2> /dev/null 92 fi 93 i=`expr $i + 1` 94 done 95 96} 97 98# 99# 0th IFD データの解析処理 100# 101# $1: ファイル 102# $2: 0th IFD のタグ数 103# 104ifd() 105{ 106 107 local i offset count position 108 109 i=0 110 111 while [ ${i} -lt ${2} ] 112 do 113 # 0th IFD のタグ情報 114 offset=`expr 22 + \( ${i} \* 12 \)` 115 # GPSInfoIFDPointer の場合はオフセットとタグ数を取得 116 if [ `get2Byte "${1}" ${offset}` -eq 34853 ] 117 then 118 position=`get4Byte "${1}" \`expr ${offset} + 8\`` 119 count=`get2Byte "${1}" \`expr ${position} + 12\`` 120 121 gps "${1}" ${count} ${position} 122 fi 123 i=`expr $i + 1` 124 done 125 126} 127 128# 処理開始 129if [ "`getString "${1}" 6 4`" = "Exif" ] 130then 131 endian=`getString "${1}" 12 2` 132 133 ifd "${1}" `get2Byte "${1}" 20` 134fi

2013/11/11
grep -o
少々前の話ではあるが、某ブログ にて
grep -o について言及する記事が出ていた。
非常に便利そうな機能ではあるのだが、
POSIX (IEEE Std 1003.1, 2013 Edition) 準拠ではなく独自拡張の機能の様なので
POSIX の範囲での実現方法を考えてみた。
例えば
$ grep -o 'href="[^"]*"'
は
$ sed -n 's/.*\(href="[^"]*"\).*/\1/p'
で代用可能なので、
$ cat << EOF | sed -n 's/.*\(href="[^"]*"\).*/\1/p' <!DOCTYPE html> <html> <body> <a href="http://aho.aho" target="_blank">あほ</a> <img src="aho.jpg" alt="aho">エロい画像</a> </body> </html> EOF href="http://aho.aho"という結果が得られる。
素晴らしい! POSIX 準拠なコマンドで POSIX 非準拠をぶち破ったぞ!
論破! 論破! 論破!
ただし grep (1) の -E オプションは POSIX に準拠しているが、 sed (1) の -E オプションは POSIX に定義されていないので、
$ grep -o -E '(src|href)="[^"]*"'
には対応できない。FreeBSD の sed (1) など -E オプションが利用できれば
$ sed -n -E 's/.*((src|href)="[^"]*").*/\1/p'
とする事で対応できるのだが、
$ cat << EOF | sed -n -E 's/.*((src|href)="[^"]*").*/\1/p' <!DOCTYPE html> <html> <body> <a href="http://aho.aho" target="_blank">あほ</a> <img src="aho.jpg" alt="aho">エロい画像</a> </body> </html> EOF href="http://aho.aho" src="aho.jpg"POSIX の範疇を逸脱した時点で grep -o を使えば良いとなってしまう。
残念っ!
2013/11/23 追記
頑張る必要は全くありません(笑)普段は GNU の便利なオプションも使っていますし、 POSIX 準拠していないコマンドやオプションも使ってます。
純粋に楽しいからやってるだけです。
2013/10/30

2013/10/02
国別フィルタの自動生成ツール
bsdhack.org ドメインは FreeBSD でサーバを構築しているのだが、
特定の国からのアタックや迷惑メイルが非常に多いので
ipfw (8) によるフィルタリングを利用して
指定した国からのパケットを拒否する設定を自動生成するツールを作成した。
APNIC から IPアドレスの割当リストを取得して、
IPアドレスを CIDR 型式に修正した上で
ipfw (8) のコマンドラインパラメタを自動生成している。
スクリプトは FreeBSD の ipfw (8) 向けだが、
出力部分を適宜修正する事で Linux の iptables (8) 向けの
設定も出力可能だと思う。
1#!/usr/bin/perl 2use Socket; 3 4# IP アドレス割当リスト取得 URL 5$url = "http://ftp.apnic.net/stats/apnic/delegated-apnic-latest"; 6 7# FreeBSD の ipfw (8) のルール番号 8if(@ARGV < 1){ 9 $rule = 2000; 10} 11else{ 12 $rule = $ARGV[0]; 13} 14 15# 拒否対象の国コード 16@country = ('KR', 'CN'); 17 18foreach $i (@country){ 19 $country{$i} = 1; 20} 21 22if(open(IN, "fetch -q -o - $url|")){ 23 # 拒否対象の国の場合は IP アドレスを保存 24 while(<IN>){ 25 if(/^apnic\|(..)\|ipv4\|(\d+.\d+.\d+.\d)\|(\d+)/){ 26 if($country{$1}){ 27 $table{inet_aton($2)} = $3; 28 } 29 } 30 } 31 close(IN); 32 33 # 取得した IP 割当リストから開始アドレスと個数を取得 34 foreach $net (sort keys %table){ 35 $addr = unpack('N', $net); 36 $num = $table{$net}; 37 while($num == $num[0] && ($addr ^ $addr[0]) == $num){ 38 shift @addr; 39 shift @num; 40 $addr &= ~$num; 41 $num <<= 1; 42 } 43 unshift(@addr, $addr); 44 unshift(@num, $num); 45 } 46 47 # IP アドレスと個数を CIDR 型式に変換して出力 48 while (@addr){ 49 for($num = pop(@num), $mask = 32; $num > 1; $num >>= 1, $mask--){} 50 $filt = inet_ntoa(pack('N', pop(@addr))) . "/$mask"; 51 # FreeBSD の ipfw(8) 向け出力 52 print "\${fwcmd} add $rule deny ip from $filt to any in recv \${wan}\n"; 53 # Linux の iptables(8) 向け出力 54 # print "\${iptables} -A INPUT -s $filt -j DROP\n"; 55 $rule++; 56 } 57} 58 590;
FreeBSD の場合は WAN 側のインタフェイス名が '${wan}' 変数に、 iptables コマンドの実行ファイル名が '${ipfw}' 変数に それぞれ格納されている事を前提としたスクリプトになっているので、 利用する際は適宜変更しながら使って下さい。
